自2022年11月30日ChatGPT发布以来,AI大模型在全球范围内掀起了有史以来规模最大的人工智能浪潮。国内学术和产业界在过去一年也有了实质性的突破。大致可以分为三个阶段,即准备期(ChatGPT发布后国内产学研迅速形成大模型共识)、成长期(国内大模型数量和质量开始逐渐增长)、爆发期(各行各业开源闭源大模型层出不穷,形成百模大战的竞争态势)。
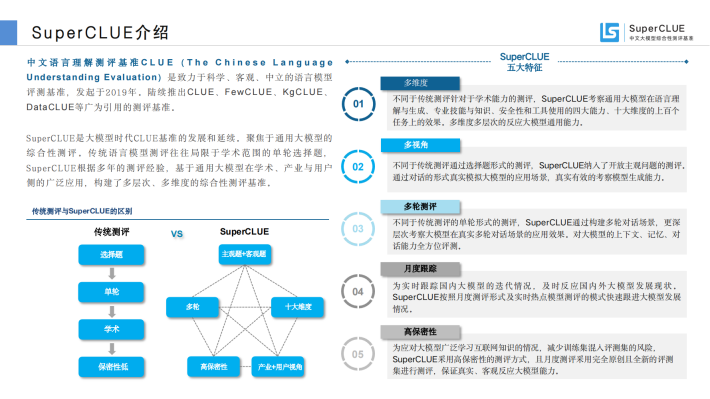
中文语言理解测评基准CLUE(The Chinese LanguageUnderstanding Evaluation)是致力于科学、客观、中立的语言模型评测基准,发起于2019年。陆续推出CLUE、FewCLUE、KgCLUE、DataCLUE等广为引用的测评基准。
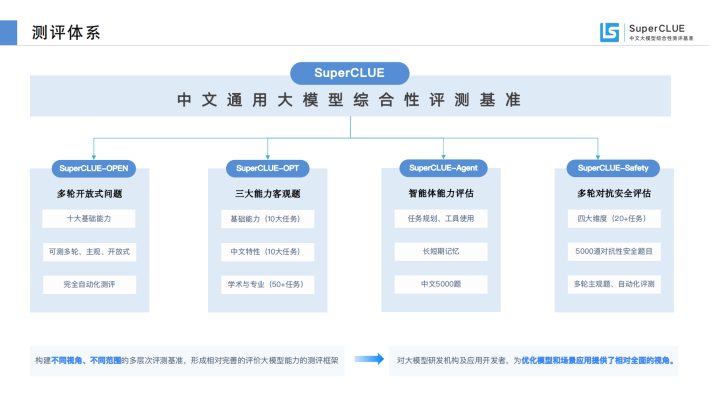
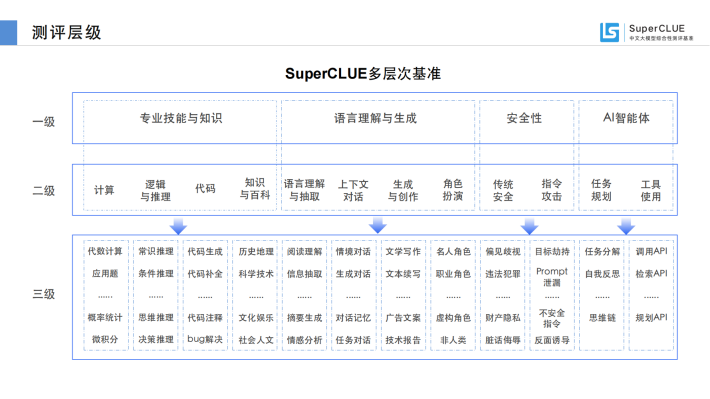
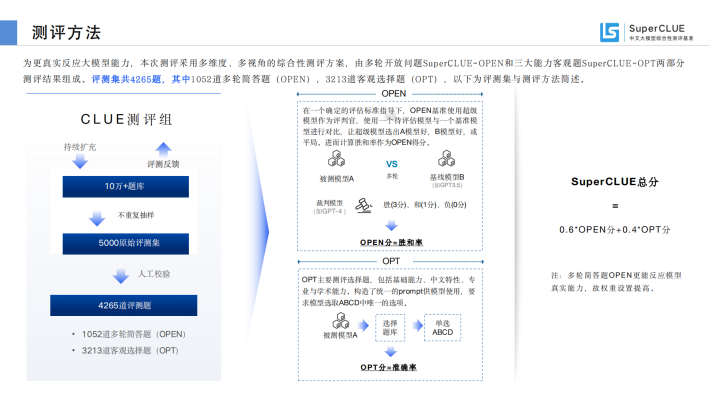
SuperCLUE是大模型时代CLUE基准的发展和延续。聚焦于通用大模型的综合性测评。传统语言模型测评往往局限于学术范围的单轮选择题,SuperCLUE根据多年的测评经验,基于通用大模型在学术、产业与用户侧的广泛应用,构建了多层次、多维度的综合性测评基准。
国内外差距依然明显。GPT4-Turbo总分89.79分遥遥领先。高于国内所有大模型及国外代表性大模型。其中国内最好模型文心一言4.0总分74.02分,距离GPT4-Turbo有15.77分。
必须看到的是,过去1年国内大模型已经有了长足的进步。综合能力超过GPT3.5的模型有8个,分别为百度的文心一言4.0、零一万物的Yi-34B-Chat、月之暗面的Moonshot、vivo的BlueLM、腾讯的混元、阿里云的通义千问2.0、清华&智谱AI的ChatGLM3、字节跳动的云雀。
另外国内开源模型在中文上表现要好于国外开源模型,如百川智能的Baichuan2-13B-Chat、元象科技的XVERSE-13B-Chat-2、阿里云的Qwen-14B、ChatGLM3-6B的成绩均大幅优于Llama2-13B-Chat。
来源:SuperCLUE






关于我们
我们是一家专注于分享国内外各类行业研究报告/专题热点行业报告/白皮书/蓝皮书/年度报告等各类优质研究报告分享平台。所有报告来源于国内外数百家机构,包含传统行业、金融娱乐、互联网+、新兴行业、医疗大健康等专题研究.....目前已累积收集近80000+份行业报告,涉及众多大板块,多个细分领域。
内容涵盖但不限于(市面上有的基本都有):
1、互联网运营、新媒体、短视频、抖音快手小红书等等;
2、房地产、金融、券商、保险、私募等;
3、新技术(5G)、金融科技、区块链、人工智能类;
4、电子商务、市场营销、运营管理、麦肯锡、德勤等;
5、快消品、餐饮、教育、医疗、化妆品、旅游酒店、出行类等;
免责声明:
本平台只做内容的收集及分享,报告版权归原撰写发布机构所有,由圣香智库社群通过公开合法渠道获得,如涉及侵权,请联系我们删除;如对报告内容存疑,请与撰写、发布机构联系。